
大数据
搭配LINUX环境
- 创建 /usr/local/hadoop 文件夹
- 下载hadoop,并解压
- 安装 JDK 环境
- 生成无密公钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa - 将公钥id_dsa.pub 添加进keys ,保证无密码登录
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys - 验证是否成功 :
ssh localhost(第一次登录有询问)
解释
- dsa 为生成的密钥类型
- -P 为密码
- ‘’ 表示无密码
- -f 后面为生成要保存的位置
Java
1 | package com.itstar.util; |
数据概念
大数据是由结构化和非结构化数据组成的
- 10%的结构化数据,储存在数据库中
- 90%的非结构化数据,它们与人类信息密切相关
HDFS的底层原理:代理对象与RPC
Hive
什么是Hive?
Hadoop : 大数据的第一个框架
| 框架 | 作用 |
|---|---|
| HDFS | 存储 |
| MapReduce | 计算 |
| YARN | 调度 |
解释 : Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化(行对行、列对列)的数据文件映射为一张表,并提供一种类SQL(HQL)的功能
- 优缺点
- 优点
- 提供了SQL的查询,提供快速开发的能力
- 避免了去写 MR(MapReduce),减少开发人员成本
- 底层实现是 MR
- 适合处理大数据量,对于小数据量没有优势,延迟高
- 缺点
- 数据挖掘领域不擅长
- 效率相对较低,MR 不够智能
- 调优比较困难
- 优点
Hive 的架构原理
Hive 原理架构
- Meta store ==> derby | mysql
- Driver : 解析器 、 编译器 、 优化器 、 执行器
- MapReduce
- HDFS
Hive 与数据库比较
查询语言
- HQL 与 SQL 、 自定义函数 (UDF、UDAF、UDFF)
数据的储存位置
- Hive 存在HDFS 中
- 数据库: 本地文件系统中、块设备
- 数据更新
- Hive 内容 读多写少
- 数据库: 增删改查
- 执行 和 执行延迟
- 扩展性
- Hive 比 Mysql 强
Hive 的数据类型
- 基本数据类型
| Hive 的数据类型 | Java 数据类型 |
|---|---|
| Tinyint | byte |
| SMALINT | short |
| INT | int |
| BIGINT | long |
| BOOLEAN | boolean |
| FLOAT | float |
| DOUBLE | double |
| STRING | string |
| TIMESTAMP | 时间类型 |
| BINARY | 字节数组 |
- 集合数据类型
STRUCT 、 MAP 、 ARRAY
- 类型转换
和 Java 的类型转换一致,如果是 低 -> 高 自动转
DDL数据定义与DML数据操作
小范例
MAP : kv 结构
STRUCT : 不单单只是类型,而且还有类型名
建表语句: Json 格式
1 | create table test( |
数据操作
1. 创建数据库: create database if not exists db_hive; // 默认路径: /user/hive/warehouse
create database if no exists jedieal location '/jedieal.db'; // 使用 location 指定路径
2. 修改数据库: alter database jedieal set dbproperties(‘create’=’20180724’); // 加上创建时间,即自定义的元数据(记录了数据的相关信息)
desc database extended jedieal;
3. 查询数据库: show database;
show database like ‘db_hive*’;
4. 删除数据库: drop database db_hive;
5. 创建数据表:
- 普通创建表
1
2
3
4
5
6create table if not exists student (
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student'
根据查询结果创建表 (查询的结果会添加搭配新建的表中)
`create table if not exists student as select id, name from student;`根据已经存在的表结构创建表
create table if not exists emp like emp1;
| Table Type | |
|---|---|
| MANAGED_TABLE | 内部表 |
| EXTERNAL_TABLE | 外部表 |
外部表与内部表的区别:
- 删内 : 会把表结构和表里的数据都删除
- 删外 : 只会删除表结构、不会删除表数据
- drop table 表名;
6. 分区数据表:1
2
3
4
5create external table dept_partition_external (
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
分区及分文件夹
分桶及文件
修改数据表:
删除数据表:
企业级优化
Fetch 抓
/hive.fetch.task
三个:
- more
- minimal
- none
1
2
3set hive.fetch.task.conversion=none;
set hive.fetch.task.conversion=more;
本地模式
1 | #开启本地 MR |
查询分桶表:select * from emp cluster by deptno;
严格模式
1 | select * from emp; |
MapReduce
日志的固定格式:
访问时间 用户ID 查询词 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
需求: 分析搜索结果中,排名第一,点击率第二的日志信息

一、 使用MapReduce
- 原理:
- 根据Google发表的一篇论文提出: MapReduce计算模型
- MapReduce的问题来源: PageRank问题 (网页排名)
- 实战:
- 依赖的jar包
二、 使用 Spark
- 原理:
三、 使用 Hive
- 原理:
四、 大数据项目标准、架构
Hadoop
Hadoop 简介
Hadoop 简介
- Hadoop 是 Apacha 软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
- Hadoop是基于 Java 语言开发的,具有跨平台的特性,也可以部署在廉价计算机集群中
- Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System) 和 MapReduce
- Hadoop是行业大数据标准开源软件
Hadoop 发展
Hadoop由Apache Lucene 项目创始人 Doug Cutting 开发的文本搜索库,源自 Apache Nutch 项目
- 2004, Nutch 模仿 GFS 开发了HDFS的前身 NDFS (Nutch Distributed File System)
- 2004, 谷歌公司发表一篇阐述 MapReduce 分布式编程思想的论文
- 2005, Nutch 开源实现谷歌的 MapReduce
- 2006, NDFS、MapReduce 独立成为 Hadoop
- 2008, Hadoop 正式成为 Apache 顶级项目
Hadoop 特性
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在 Linux 平台上
- 支持多种编程语言
国内采用 Hadoop 的公司: 百度、淘宝、网易、华为、中国移动
其中淘宝的Hadoop集群较大
Hadoop 应用


Hadoop 版本
第二代 Hadoop 包含两个版本 : 0.23.x 和 2.x
这两个版本完全不同于Hadoop1.0,是一套全新的架构,包含 HDFS Federation 和 YARN 两个系统。相对0.23.X , 2.X 增加了 NameNode HA 和 Wire-compatibility 两个特性

Hadoop 生态系统
Hadoop 组图

生态系统组件解释

Hadoop 安装与使用
一、 Linux
推荐选择Ubuntu操作系统,建议使用64位系统版本的Linux。若电脑的配置较好,推荐使用虚拟机安装
二、 Hadoop安装方式
- 单机模式: Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。
非分布式即单 JAVA 进程,方便进行调试
- 伪分布式模式: Hadoop 可以在单节点上以伪分布式的方式运行
Hadoop进程以分离的 java 进程来运行,节点即作为 NameNode 也作为 DataNode, 同时读取的是 HDFS 中的文件
- 分布式模式: 使用多个节点构成集群环境来运行Hadoop
注意:Hadoop不会覆盖结果文件
HBase介绍
HBase访问接口
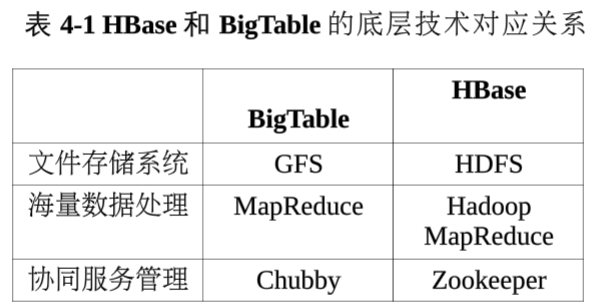
一、 BigTable
BigTable是一个分布式存储系统。起初用于解决典型的互联网搜索问题
特点
(1) 使用谷歌的MR分布式并行计算模型来处理海量数据
(2) 使用谷歌分布式文件系统GFS作底层数据存储
(3) 使用Chubby提供协同服务管理
(4) 具有广泛的应用性、可扩展性、高性能和高可用性等
(5) 谷歌的许多项目存储在BT中,如搜素、地图,另外还有YouTube等
建立互联网索引
(1) 爬虫抓取新页面,将页面每页一行的方式存储至 BigTable
(2) MR计算作业运行在整张表上,生成索引,为网络搜素提供准备
搜索互联网
(1) 用户发起搜索请求
(2) 网络搜索应用查询建立好的索引,从BigTable得到网页
(3) 搜索结果返回给用户
HBase介绍
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BT的开源实现。
用途:
- 存储非结构化和半结构化的松散数据
- 处理非常庞大的表,通过水平扩展的方式,由廉价计算机集群处理庞大的数据表
对比BT与HBase
HBase关系数据库
(1) 数据类型:
HBase数据库采用相对传统关系数据库更为见到那的数据模型,把数据存储为未经解释的字符串
(2) 数据操作:
只包含简单的插入、查询、删除、清空等,避免了复杂表和表之间的关系
(3) 存储模式:
关系数据库基于行模式存储的,而HBase是基于列存储的,不同的列族文件是分离的,每个列族由几个文件保存
(4) 数据索引:
关系数据库通常针对不同列构建复杂的多个索引,而HBase只有一个索引/行键,以至所有的访问方法,或通过行键访问,或通过行键扫描,从而系统不会停滞
(5) 数据维护:
关系数据库更新操作会将新值覆盖旧值,而HBase更新操作不会删除旧数据版本、而是生成一个新的版本,旧版本仍然保留
(6) 可伸缩性:
关系数据库难以实现横向扩展,而纵向扩展空间有限,而HBase和BT分布式数据库可以灵活的水平扩展,通过在集群中增加或减少硬件数量来实现性能伸缩
SQL操作
select * from db where ; : 从 db 中查看所有数据, where 为条件查询

