
机器学习
基础概念
-
训练集 :用于训练机器学习算法的数据样本集合 为算法输入大量已分类数据作为算法的训练集
-
特征(属性) : 通常是训练样本集的列,是独立测量得到的结果,多个特征联系起来在一起共同组成一个训练样本
-
特征类型
- 数值型,可以使用十进制数字
-
目标变量
- 分类算法中目标变量的类型通常是标称型的,被称为类别
-
回归算法的类型通常为连续型的
-
知识表示
- 检查机器是否已经学会了所分配的任务
监督学习
内容:分类 & 回归
目的:进行预测,对目标变量的分类信息进行预测
回归
主要用于预测数值型数据
无监督学习
特点:无类别信息,也不会给定目标值
聚类 : 将数据集合分成由类似的对象组成的多个类的过程
密度估计 : 将寻找描述数据统计值的过程
Day_1
步骤一 —— 导入必需数据科学库
在进行数据分析,需要两个必须常用库 —— pandas 、 Numpy
import numpy as np import matplotlib.pyplot as plt import pandas as pd
步骤二 —— 设置工作目录,导入数据集
数据集一般为.csv格式,且通常为表格形式。每一行都有对应的数据记录。每一个数据集都会包括两部分,独立变量(independent variable)和依赖变量(dependent variable)。
我们使用pandas中的read_csv的方式来读取数据集的内容,然后可以在Dataframe中分离矩阵和相关和不相关的向量
数据科学中很重要的一点就是建立metrics(度量,指标)。每一列都可以是一个metric。
而metrics主要包括两部分:independent variable 和 dependent variable。
getwd() setwd("/working directory") dataset = pd.read_csv(filepath_or_buffer=" ") # create 独立变量vector X = dataset.iloc[ : , : -1].values # 除了最后一列全是自变量 # create 依赖变量vecto Y = dataset.iloc[ : , 3].values # 最后一列作为应变量 View(dataset)
解释
iloc表示取数据集中的某些行和某些列- 逗号前表示行,逗号后表示列
- 这里表示取所有行,列取除了最后一列的所有列,因为列是应变量
机器学习的目的就是需要通过独立变量来预测非独立变量(prediction)。独立变量不会被影响而非独立变量可能被独立变量影响。
步骤三 —— 缺失值处理
关于缺失值(missing value)的处理,在sklearn的preprocessing包中包含了对数据集中缺失值的处理,主要是应用Imputer类进行处理
进行处理的数据集中包含缺失值一般步骤如下:
- 使用字符串'nan'来代替数据集中的缺失值;
- 将该数据集转换为浮点型便可以得到包含np.nan的数据集;
- 使用sklearn.preprocessing.Imputer类来处理使用np.nan对缺失值进行编码过的
from sklearn.preprocessing import Imputer imputer = Imputer(missing_values= "NaN", strategy= "mean", axis= 0) imputer = imputer.fit(X[ : , 1: 3]) # (inclusive column 1, exclusive column 3, means col 1 & 2) X[ : , 1: 3] = imputer.transform(X[ : , 1: 3]) # 将imputer 应用到数据
注意在data science中我们可以用NaN代替空值,但是在ML中必须要求数据为numeric。所以我们可以用mean来代替空值。
步骤四 —— 分类数据编码
分类数据一般包含标签分类值,而不是数据值。可能的变量通常限制在固定数据集中。单纯的变量值不能在数学模型等式中使用,所以我们需要对分类数据编码成数字。
作法: 从sklearn.preprocessing中导入LabelEncoder类
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() # 标准化标签,将标签值统一转换成range(标签值个数-1)范围内 X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) #不包括index行
简单来说 LabelEncoder 是对不连续的数字或者文本进行编号
再创建一个虚拟变量 (变量dummy化)
dummy variable是用0或1表示某个类别是否出现,适用于出现bool类型的结果
OneHotEncoder用于处理分类变量,将变量的特征值转换为稀疏矩阵
onehotencoder = Onehotencoder(categorical_features = [0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_Y = LabelEncoder() Y = labelencoder_Y.fit_transform(Y)
步骤五 —— 将数据集分成 测试集 和 训练集
将数据集分为两个部分,一个训练集,另一个用来测试所建立的模型的表现。
通常分配数据比例为 80/20 。
接下来采用从sklearn.model_selection库中导入train_test_split()类
from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size= 0.2, random_state= 0)
注意:原来的cross_validation模块被弃用了,改为支持model_selection这个模块
步骤六 —— 特征缩放 (Feature scaling)
feature scaling(特征缩放)的思想就是将所选特征的value都缩放到一个大致相似的范围
通常来说,大部分机器学习算法都采用欧氏距离来计算两地的距离。特征在不同的量级、单位、排列上的极度不同会产生问题。高量级的数据的欧式距离的计算量会很大。
由于每个变量的范围不同,如果两个变量之间差距太大,会导致距离对结果产生影响。所以我们要对数据进行一定的标准化改变。最简单的方式是将数据缩放至[0.1]或者[-1,1]之间:
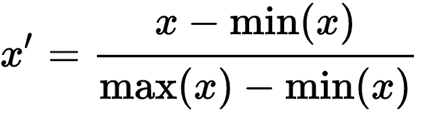
为使得特征标准化或Z-score统一化,需要导入 sklearn.preprocessing中的StandardScalar
代码如下:
from sklearn.preprocessing import StandardScalar sc_X = StandardScalar() X_train = sc_X.fit_transform(X_train) X_test = sc_X.fit_transform(X_test)
第一天的学习结束啦,开心😄
Day_2 简单线性回归
概述
- 使用一个简单的特征来预测将来值
线性回归是一种基于非独立变量X来预测独立变量Y的方法。它假设两个变量线性相关,因此,我们需要找出X与Y的线性关系
- 如何寻找最合适的线来拟合
在回归模型中,如果我们能够找到能使预测误差最小的线来拟合,则回归线的误差也会最小化。
我们应该试图将以观察到的值与我们预测值之间的距离最小化。
y = bo + b1*x1
步骤一、处理数据
运用第一天的五个步骤
- Import the Libraries
- Import the DataSet
- Check for Missing Data
- Split the DataSet
- Feature Scaling
import pandas as pd import numpy as np import matplotlib.pyplot as plt dataset = pd.read_csv('studentscores.csv') X = dataset.iloc[ : , : 1 ].values Y = dataset.iloc[ : , 1 ].values from sklearn.cross_validation import train_test_split X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0)
使用
matplotlib.pyplot绘制图
注意:这里我们没有进行特征缩放,这是因为一般Python的library会自动进行feature scaling,所以我们不需要自己动手
步骤二、训练训练集的简单线性回归模型
下面我们将通过训练集的X_train与y_train 计算出符合训练集的曲线
为了训练数据集,我们将使用sklearn.linear_model调用LinearRegression,使用regressor对象
我们将使用LinearRegression类,fit()方法将对象拟合到数据集中。
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor = regressor.fit(X_train, Y_train) # 通过train集找到曲线
步骤三、预测结果
我们将从训练集中预测结果,将输出保存在向量Y_pred.为了预测结果,我们将使用在上一步中在regressor中使用的LinearRegression类方法
Y_pred = regressor.predict(X_test)
将测试集的X_test 带入得到的曲线中,得到预测的结果y_pred,目的是为了将预测结果y_pred与测试集中的y_test进行比较,看看是否符合分布,从而确定预测是否准确
步骤四、数据可视化
最后一步为将我们的结果可视化。我们将使用matplotlib.pyplot库来制作训练集结果和测试集结果的扩散图(scatter plot),来观察我们的模型对结果值的预测情况
- 可视化训练结果
plt.scatter(X_train, Y_train, color= 'red') plt.plot(X_train, regressor.predict(X_train), color= 'blue') ply.title(" ") #显示整个图标的标题 plt.xlabel(" ") # 显示X坐标的标题 plt.ylabel(" ") # 显示Y坐标的标题 plt.show()
- 可视化测试结果
# Import the test results plt.scatter(X_test, Y_test, color= "red") plt.plot(X_test, regressor.predict(X_test), color= "blue") ply.title(" ") #显示整个图标的标题 plt.xlabel(" ") # 显示X坐标的标题 plt.ylabel(" ") # 显示Y坐标的标题 plt.show()
第2️天的学习结束啦,开心😄
Day_3 多重线性回归
概述
多重线性回归(Multiple Linear Regression)将会不只有一个自变量,并且每个自变量拥有自己的系数且符合线性回归。
多重线性回归试图使用两个或者以上的特征建立模型来适应观察线性数据。其实多重线性回归建立的步骤与简单线性回归相似。
你可以用它来找出哪一个因素对预测的输出有着最大的影响,以及不同的变量是如何相互关联的。
y = bo + b1x1 + b2x2 + ... + bnxn
需要满足的条件
- 满足线性性(linearity) :独立变量和非独立变量需要满足线性性
- 应保持误差的同方差(常方差 Homoscedasticity)
- 多元正态性(Multivariate normality):多元回归假设残差是正态分布的
- 错误的独立性(independence of errors) :每一个变量产生的错误将会独立的影响预测结果,不会对其他变量产生影响
- 缺乏多重共线性(lack of multicollinearity):假设在数据中很少或没有多重共线性,当特征(或独立变量)彼此不独立时发生多重共线性。
虚拟变量
在回归模型中,具有固定和无序数量值的数据值,在回归预测中我们需要所有的数据都是numeric的,但是会有一些非numeric的数据,例如性别 (男/女),这些值会被虚拟变量代替。变量包含例如 0/1的值,,来代替表示2代表分类值的存在与否
虚拟变量陷阱
虚拟变量陷阱是两个或多个变量高度相关的场景。
通俗来理解(intuitively),就是一个变量必须被其余变量所预测。直观地说,有一个重复(duplicate)的范畴:如果我们放弃男性范畴,它在女性范畴中是固有定义的(零女性值表示男性,反之亦然vice-versa)。
再通俗地理解,就拿性别来说,其实一个虚拟变量就够了,比如 1 的时候是“男”, 0 的时候是"非男",即为女。如果设置两个虚拟变量“男”和“女”,语义上来说没有问题,可以理解,但是在回归预测中会多出一个变量,多出的这个变量将会对回归预测结果产生影响。 部分文字信息来自Dykin' Blog
虚拟变量陷阱的解决方法:
删除分类变量中的一个——如果有M个类别,在模型中使用M-1,可以忽略掉的值作为参考值。
y = bo + b1x1 + b2x2 + b3D1
注释--建立模型(stepwise Regression)
有多种方法来选择适当的变量,例如:
- 前向选择(前进法Forward Selection)
- 逆向消除(后退法Backward Elimination)
- 双向比较(bi-directional comparision)
Backward Elimination:
首先包含了所有的feature,然后每个feature都尝试去删除,测试删除的哪个feature对模型准确性有最大的提升,最终删掉对模型提升最高的一个特征。如此类推,直到删除feature并不能提升模型为止。
开始今天的学习
预处理数据
运用第一天的处理步骤
- Import the libraries
- Import the DataSet
- Check for Missing Data
- Encode Categorical Data
- Make Dummy Variables if necessary and avoid dummy variable trap
- Feature Scaling will be taken care by the Library 3
代码如下:
import pandas as pd import numpy as np import matplotlib.pyplot as plt dataset = pd.read_csv('50_Starups.csv') X = dataset.iloc[ : , :-1].values Y = dataset.iloc[ : , 4].values # Encoding Categorical data from sklearn.preprocessing import LabelEncoder, OneHotencoder labelencoder = LabelEncoder() X[ : , 3] = labelencoder.fit_transform(X[ : , 3]) onehotencoder = Onehotencoder(categorical_features= [3]) X =onehotencoder.fit_transform(X).toarray() # Avoiding Dummy Variable Trap X = X[ : , 1: ] #从1 开始,并非0 # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
将模型拟合到训练集 (Fitting our model to the trainning set)
这个步骤和简单线性回归完全相同。
我们将使用 sklearn.linear_model库中的LinearRegression类来拟合训练集,然后创建一个LinearRegression的regressor对象,再对对象使用fit()方法来处理。
# Fitting Multiple Linear Regression to the Training set from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, Y_train)
预测测试集的结果
在这个步骤中,我们将预测从测试集观察到的结果。使用Y_pred来储存输出,最后使用predict()方法,来预测我们在上一步骤中训练的结果
# Predicting the test set results Y_pred = regressor.predict(X_test) plt.scatter(np.arange(10),y_test, color = 'red',label='y_test') plt.scatter(np.arange(10),y_pred, color = 'blue',label='y_pred') plt.legend(loc=2) plt.show()
第3天的学习结束啦,明天也要坚持哟😄
Day_4 逻辑效果(logistic regression)
概述
逻辑回归在某些书中也被称为对数几率回归,逻辑回归适合于处理分类问题,目的在于预测当前对象属于哪个分类组,它给出了一个0到1之间的离散二进制结果。
一个非常典型的例子就是一个人到底会不会为即将到来的选举投票
疑问
它是如何工作的???
逻辑回归通过依赖于它的基本逻辑函数估计概率,来测量因变量(我们想要预测的标签)和一个或多个独立变量(我们的特征)之间的关系。
Sigmoid Function (S型曲线函数)
SigMoid函数是一个S形曲线,它可以取任何实数,并将其映射到0到1之间的值,但绝对不受这些限制。
\phi (z) = \dfrac{1}{1 + e^{-z}}
进行预测
概率必须转化为二进制值(binary),以便实际进行预测。这是Logistic函数的任务,也称为乙状函数(Sigmoid function)。0和1之间的值将使用阈值分类器(threshold classifier)转换成0和1。
逻辑 vs 线性
逻辑回归给你一个离散(discrete [dɪˈskri:t] )的结果,但线性回归给出了一个连续(continuous)的结果。

